2026 model brief
ChatGPT vs Claude vs Gemini
A current 2026 comparison of GPT-5.5, Claude Opus 4.8, Gemini 3.5 Flash, the unreleased Gemini 3.5 Pro, coding strength, pricing, context windows, tool surfaces, and what each ecosystem is actually best at.
ChatGPT vs Claude vs Gemini: which should you pick right now?
There is still no honest universal winner. The meaningful split is platform shape, not fan sentiment. OpenAI has the broadest all-around product surface. Anthropic now has the strongest generally available public coding-agent case with Claude Opus 4.8. Google has the strongest ecosystem leverage when search, Workspace, Vertex, Android, multimodal routing, or cost control already matter to your stack.
The May 2026 update matters because two things changed at once. Anthropic released Claude Opus 4.8 on May 28, 2026, with stronger results than Opus 4.7 across software engineering, agentic tool use, long context, and professional-work benchmarks. Google had just released Gemini 3.5 Flash and disclosed that Gemini 3.5 Pro is already in internal use but not yet generally available.
So the real question is not which model sounds smartest in a demo. It is which ecosystem makes your actual workflow cheaper, faster, and more reliable once you account for tool surface, context windows, review processes, latency, procurement, and lock-in. For unpublished models, the answer has to stay provisional. No public Gemini 3.5 Pro benchmark table exists yet.
Current product snapshot (May 28, 2026)
These are the current product facts that matter most when you are choosing an ecosystem rather than arguing about one benchmark chart.
| Ecosystem | Current read | Useful numbers | Best fit | Main watchout |
|---|---|---|---|---|
| ChatGPT / OpenAI | Broadest all-around platform | GPT-5.5 is priced at $5 in / $30 out with a 1M-token API context window; GPT-5.5 Pro is priced at $30 in / $180 out; OpenAI still has the broadest tool and product surface. | Teams that want one vendor across chat, API, search, code, computer use, and execution. | Higher flagship pricing than GPT-5.4 and a very broad surface area that can encourage deeper lock-in. |
| Claude / Anthropic | Strongest public coding-agent case | Claude Opus 4.8 uses model ID claude-opus-4-8, keeps the same regular Opus price at $5 in / $25 out, adds a fast mode priced at $10 in / $50 out, and improves over Opus 4.7 on nearly every capability benchmark Anthropic reports. | Codebase work, long-horizon tasks, document-heavy reasoning, tool orchestration, and higher-trust agent execution. | Still premium-priced, with a narrower surrounding product surface than OpenAI or Google. Production teams should rerun prompts, evals, latency checks, token budgets, screenshots, and tool workflows before migration. |
| Gemini / Google | Best ecosystem leverage play | Gemini 3.5 Flash is public and posts strong tool/workflow signals, including 83.6 on MCP Atlas and 57.9% on Finance Agent v2 in Anthropic's comparison table. Gemini 3.5 Pro is disclosed by Google as internal and expected next month, not yet public. | Google-heavy stacks, search-grounded workflows, multimodal apps, Android/Workspace/GCP workflows, and cost-sensitive routing. | Gemini naming, preview status, surface differences, and the lack of public Gemini 3.5 Pro benchmarks create buyer confusion. |
The benchmark trap is still the easiest way to buy the wrong model
The current official product pages are more informative than most benchmark threads because they expose what the vendors are actually selling. OpenAI is selling an ecosystem with built-in tools, search, and execution. Anthropic is selling reliability on coding, agentic work, computer use, long context, and high-trust review. Google is selling model capability plus grounding, multimodality, distribution, and cloud leverage.
That is why raw benchmark talk is often a distraction. The most expensive failure mode is not picking the model that scored two points lower on a leaderboard. It is picking the ecosystem that forces awkward routing, weak governance, higher review burden, or a tool stack your team will not really use.
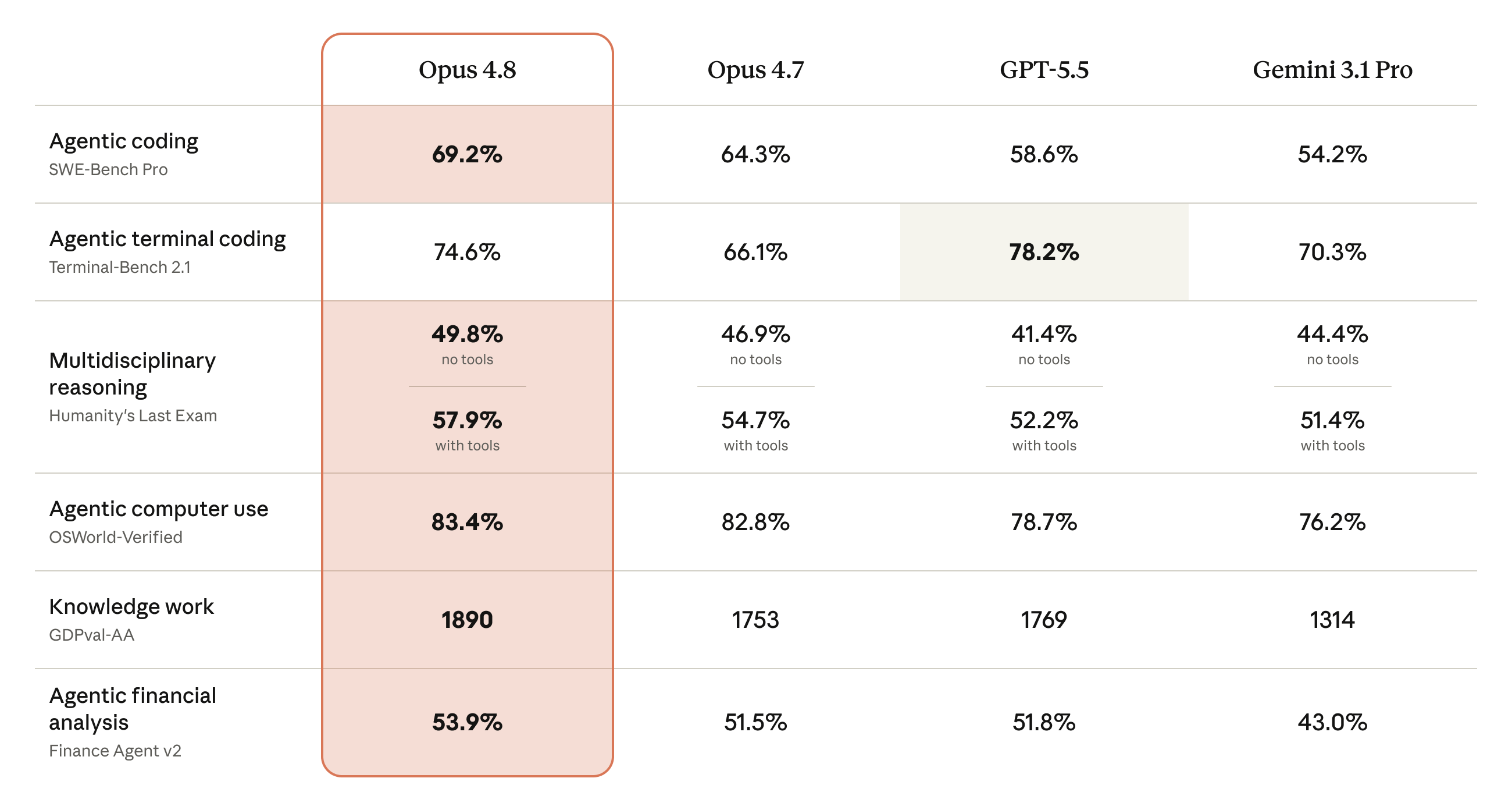
Current benchmark snapshot: Opus 4.8 changes the Claude read
The useful move is not to crown one model from one vendor table. Read the benchmarks by workload: code repair, terminal work, knowledge work, browser/search tasks, computer use, tool orchestration, and long-context reliability each tell a different story.
| Benchmark | Current numbers | What it means |
|---|---|---|
| SWE-bench Pro | Opus 4.8: 69.2%; Opus 4.7: 64.3%; GPT-5.5: 58.6%; Gemini 3.1 Pro: 54.2% in Anthropic's comparison table. | Claude Opus 4.8 is now the cleaner published code-repair leader among the generally available models covered here. |
| SWE-bench Verified | Opus 4.8: 88.6%; Opus 4.7: 87.6%; Gemini 3.1 Pro: 80.6%. Claude Mythos Preview is higher in Anthropic's gated-model material, but it is not generally available. | Anthropic's public Opus tier improved, but the company's own safety material says its gated Mythos-class model remains the higher capability frontier. |
| Terminal-Bench 2.1 | GPT-5.5: 78.2%; Opus 4.8: 74.6%; Gemini 3.1 Pro: 70.3%; Opus 4.7: 66.1% in Anthropic's table. Google reports Gemini 3.5 Flash at 76.2 on its May 2026 launch post. | OpenAI still deserves first evaluation for CLI-heavy developer agents, while Opus 4.8 materially narrows the gap and Gemini 3.5 Flash is no longer a lightweight-only footnote. |
| GDPval-AA knowledge work | Opus 4.8: 1890 Elo; GPT-5.5: 1769; Opus 4.7: 1753; Gemini 3.1 Pro: 1314 in Anthropic's table. Google reports Gemini 3.5 Flash at 1656 Elo. | Claude has the strongest current public professional-work signal in this table, but score formats differ across GDPval reporting, so local workflow tests still matter. |
| Finance Agent v2 | Gemini 3.5 Flash: 57.9%; Opus 4.8: 53.9%; GPT-5.5: 51.8%; Opus 4.7: 51.5%; Gemini 3.1 Pro: 43.0%. | Google's public Flash model has a real financial-research signal. Gemini 3.5 Pro should not be scored until Google publishes comparable numbers. |
| OSWorld-Verified computer use | Opus 4.8: 83.4%; Opus 4.7: 82.8%; GPT-5.5: 78.7%; Gemini 3.1 Pro: 76.2%; Gemini 3.5 Flash: 78.4% in Anthropic's table. | Claude has the strongest published computer-use score here, but VM setup, action budget, screenshot handling, and tools make direct product tests essential. |
| BrowseComp and search-heavy work | Opus 4.8: 84.3% single-agent and 88.5% multi-agent in Anthropic's system card. GPT-5.5: 84.4%, GPT-5.5 Pro: 90.1%, and Gemini 3.1 Pro: 85.9% in existing OpenAI/Anthropic comparison tables. | Search-heavy assistants should keep OpenAI and Gemini in the routing pool even if Claude is the default for code or document reasoning. |
| MCP Atlas and tool use | Gemini 3.5 Flash: 83.6%; Opus 4.8: 82.2%; Opus 4.7: 79.1%; Gemini 3.1 Pro: 78.2%; GPT-5.5: 75.3%. | The tool-use picture is not one-sided. Google and Anthropic are both credible for protocol-style tool orchestration. |
| GPQA Diamond | Gemini 3.1 Pro: 94.3%; Opus 4.7: 94.2%; Opus 4.8: 93.6% in Anthropic's table. | At this tier, graduate-level reasoning is tightly clustered. Vendor fit, tools, pricing, governance, and latency usually matter more than tenths of a point. |
Cost-normalized benchmark check
A raw benchmark win is only half the story. Real agent cost includes input tokens, cached input tokens, output tokens, hidden or billed reasoning tokens, retries, tool calls, file search, batch discounts, and long-context surcharges.
| Benchmark read | Cost question | Why it changes the recommendation |
|---|---|---|
| Claude Opus 4.8 leads the strongest public coding-agent rows in this page. | How many total tokens does the task burn at Opus pricing, including reasoning and retries? | Opus can still be the right answer for hard engineering work, but a cheaper model with more attempts may win routine tasks if review quality holds. |
| GPT-5.5 leads Terminal-Bench 2.1 in Anthropic's comparison table. | Does the CLI task require expensive tool execution, long context, or repeated failed runs? | Terminal scores should be paired with successful-task cost, not just pass rate. |
| Gemini 3.5 Flash leads several cost-sensitive practical rows, including Finance Agent v2 and MCP Atlas in the cited tables. | Can the workflow use the cheaper Flash tier without creating extra review burden? | Flash-style routing can be the value leader when task success stays high and output review is cheap. |
| Unreleased Gemini 3.5 Pro and gated Claude Mythos-class models may change the frontier. | What will the public API price, output cap, reasoning-token behavior, and tool pricing be? | No unpublished model should be treated as a cost-normalized winner until both benchmark scores and billing mechanics are public. |
What matters more than benchmark fan wars
The current official sources all point to the same deeper truth: choosing a model family is really choosing an operating model.
- Consumer popularity does not equal enterprise fit. ChatGPT still dominates mainstream surface area, but Claude and Gemini win for narrower, very real reasons.
- Tooling matters as much as raw model quality. OpenAI's built-in tools, Anthropic's coding-and-computer-use emphasis, and Google's grounding stack change the value of the base model.
- Context length is only useful if the model remains reliable over long tasks and the surrounding workflow can exploit that window.
- A slightly cheaper token price can still produce a more expensive system if the vendor fit, review process, or data path is wrong.
- Unpublished models should change your roadmap, not your production default. Gemini 3.5 Pro and Claude Mythos-class models deserve watchlist status until they are actually available on your surface.
The practical choice by workflow
This is usually more useful than debating who won a single benchmark.
| Workflow | Best first look | Why |
|---|---|---|
| General-purpose AI product or internal AI platform | OpenAI | Best fit when you want the broadest mix of chat, API, tools, search, and execution in one vendor. |
| Serious codebase work and agent-style engineering tasks | Anthropic | Claude Opus 4.8 gives Anthropic the stronger generally available premium code-agent ceiling, while Sonnet remains the practical daily workhorse tier. |
| Search-grounded enterprise assistant or Google-native stack | Gemini | Google's grounding, multimodality, Vertex routing, Workspace distribution, and Android surface can become strategically meaningful very quickly. |
| Cost-sensitive multimodal workloads at scale | Gemini 3.5 Flash or OpenAI mini-tier products | Gemini 3.5 Flash is much stronger than older Flash expectations on agentic tasks, while OpenAI's smaller models still provide fallback coverage and broad tools. |
| High-trust long-context reasoning over documents | Claude or Gemini | Claude has the stronger public document/computer-use story in Opus 4.8, while Gemini adds Google-side grounding, search, and infrastructure leverage. |
| Financial research over filings | Gemini 3.5 Flash and Claude Opus 4.8 | Finance Agent v2 currently puts Gemini 3.5 Flash first and Opus 4.8 second among the public scores cited here. |
| Protocol-style tool orchestration | Gemini 3.5 Flash or Claude Opus 4.8 | MCP Atlas is close enough that your actual server set and tool-call budget should decide the default. |
| Unreleased frontier watchlist | Claude Mythos-class models and Gemini 3.5 Pro | Do not route production to unreleased models, but track them if you are planning next-quarter architecture. |
How real teams often route across the three ecosystems
Many buyers do not settle on one vendor forever. They choose a default and keep a second path for specialized work.
| Team pattern | Default choice | Secondary choice | Why |
|---|---|---|---|
| Broad internal AI rollout | OpenAI | Claude | OpenAI covers the most general ground; Claude picks up harder code or long-context reasoning tasks. |
| Engineering-heavy product team | Claude | OpenAI | Claude often wins on coding depth while OpenAI remains useful for broader product surfaces and integrations. |
| Google-native enterprise | Gemini | OpenAI or Claude | Gemini fits the surrounding stack while a second model may cover specialized coding or generalist tasks. |
| Cost-sensitive multimodal application | Gemini | OpenAI mini-tier models | The economics can be strong on Google while OpenAI provides fallback coverage and broader tools. |
| High-trust document and code workflows | Claude | Gemini | Claude makes the cleaner premium reasoning case; Gemini adds grounding and Google-side data leverage. |
Where ChatGPT is strongest
OpenAI is still the safest generalist default if you want breadth, and GPT-5.5 materially strengthens that default. It posts the strongest OpenAI-side signal for terminal work, computer use, search, knowledge work, and long-horizon tool use over GPT-5.4, and it is aimed at messy, multi-part work across code, research, spreadsheets, documents, and software interfaces.
That breadth is what makes OpenAI hard to displace. Even when another vendor is stronger on one narrow task, OpenAI often wins on total product completeness. If you need one ecosystem that can support chat experiences, APIs, coding workflows, search-grounded tasks, computer use, and tool execution, it still makes the most coherent all-around case.
Where Claude is strongest
Anthropic currently makes the sharpest public case for coding-heavy and agentic work. Claude Opus 4.8 is now the premium generally available Claude ceiling: stronger than Opus 4.7 across nearly all reported capability evaluations, with especially useful gains on SWE-bench Pro, Terminal-Bench 2.1, GDPval-AA, OSWorld-Verified, MCP Atlas, AutomationBench, GraphWalks, and USAMO 2026.
The Opus 4.8 migration details matter for real products. It uses the claude-opus-4-8 model ID, keeps regular Opus pricing at $5 / $25 per million tokens, introduces a faster but more expensive fast mode, and is wrapped in new effort controls and Claude Code workflow changes. That makes it stronger for serious agents, but it also means teams should re-benchmark prompts, cost, latency, screenshots, and token budgets before swapping it into production.
Where Gemini is strongest
Gemini is the most strategic choice when Google's surrounding assets matter. Gemini 3.5 Flash is no longer just a cheap-speed story: Google positions it as a high-speed reasoning and agentic model, and cross-source benchmark tables now give it strong signals on MCP Atlas, Finance Agent v2, Terminal-Bench 2.1, CharXiv, and GDPval-AA. Gemini 3.5 Pro is the more interesting pending question, but it is not yet public.
That matters because the Gemini choice is rarely just about model quality. It is about distribution through Google products, easier attachment to Google infrastructure, and a more natural fit for teams already living in Workspace, BigQuery, GCP, Android, or search-heavy product flows.
The current lock-in and procurement question
A lot of model comparisons still act as if the decision ends with price or benchmark scores. In real organizations, the harder question is procurement and integration gravity. OpenAI pulls you toward the richest all-purpose tool surface. Anthropic pulls you toward a narrower but often more trusted coding-and-agent stack. Google pulls you toward deeper cloud, search, Workspace, and Android integration.
That means the best choice is often the one whose surrounding product assumptions already match your team. The wrong ecosystem can force awkward wrappers, duplicated infrastructure, or workflow friction that overwhelms the headline token price.
Bottom line
Pick OpenAI if you want the broadest, most mature generalist platform and are willing to pay for that surface area.
Pick Anthropic if your hardest problem is codebase work, multi-step agent execution, document reasoning, computer-use agents, or high-trust reasoning over large contexts.
Pick Gemini if Google infrastructure, search grounding, multimodality, and routing economics are strategic advantages rather than nice-to-haves.
Track Claude Mythos-class models and Gemini 3.5 Pro for roadmap planning, but do not treat either as a production default until access, pricing, model IDs, benchmark details, and migration behavior are public.
Frequently asked questions
These are the practical questions buyers usually mean when they search ChatGPT vs Claude vs Gemini.
Which AI model is best for coding in 2026?
Claude Opus 4.8 has the strongest current public SWE-bench Pro signal among generally available Claude/OpenAI/Gemini comparison points, while GPT-5.5 remains extremely strong for terminal-heavy workflows and broad developer tooling. For product teams, that means Claude deserves first look for deep codebase reasoning and review, while GPT-5.5 deserves first look for CLI-heavy agents and broad developer workflows.
Which model is best for long context and document-heavy work?
Claude, Gemini, and GPT-5.5 all make serious long-context cases, but in different ways. Claude Opus 4.8 is compelling for document-heavy reasoning, computer use, and long-running agent work. Gemini gives Google-native teams a strong context and grounding story. GPT-5.5 keeps the broadest platform surface.
Is Gemini 3.5 Pro available?
Not broadly as of May 28, 2026. Google says Gemini 3.5 Pro is already in internal use and expected to roll out next month. Until public benchmarks, pricing, and model IDs exist, teams should compare public Gemini 3.5 Flash and Gemini 3.1 Pro numbers, then revisit the decision when Pro ships.
Should teams choose ChatGPT, Claude, or Gemini based on price alone?
Usually no. Token pricing matters, but integration cost, tool availability, review workflows, and reliability on your real tasks matter more. A cheaper model can still produce a more expensive system if it fits poorly.
Should teams standardize on one model vendor or route across several?
Many teams should do both: pick one default ecosystem to simplify governance and vendor management, then keep a second path for specialized workloads such as coding, multimodal grounding, financial research, or price-sensitive batch work. The right answer depends on how often those specialized workloads matter.
Visual source gallery
These are the current sources behind this page as of May 28, 2026. The added depth here comes from leaning on official pricing, benchmark, and model docs first, then adding market-context sources where they help explain the product landscape.
Primary release source for Opus 4.8, including pricing continuity, fast mode, effort controls, Claude Code workflow changes, and benchmark table.
Primary source for Opus 4.8 capability, safety, and benchmark details across SWE-bench, Terminal-Bench, OSWorld, MCP Atlas, GDPval-AA, Finance Agent, healthcare, multilingual, and long-context evaluations.

Primary current source for OpenAI's GPT-5.5 benchmark table, pricing, agentic coding, computer-use, knowledge-work, and safety positioning.
Best single source for OpenAI pricing and the current OpenAI tool surface, including web search, containers, batch, flex, and priority processing.

Primary Google source for Gemini 3.5 Flash, including its public release, benchmark framing, and the disclosure that Gemini 3.5 Pro is in internal use and expected next month.

Matters because Google's enterprise story is shaped by Gemini pricing, grounding charges, and routing options on Vertex.
Adds market context: ChatGPT still leads the consumer surface, Gemini has distribution pressure, and Claude is gaining traction rather than winning mass share.

Relevant systems reference on why model choice has to be evaluated alongside retrieval, policy checks, routing, observability, and business workflow design.